TOS Chat - Custom AI Chatbot
Custom GPT chatbot that allows the user to 'chat' with terms of service and privacy policy agreements. Documents are stored with Pinecone (a vector database) and queried with semantic search.
 Closed Source
Closed Source View
ViewA New Way to Read the Terms of Service
In today's digital age, it's nearly impossible to use the internet without apps and online services collecting our personal information. However, that doesn't mean we shouldn't care about our privacy. I believe that every person should understand what they’re agreeing to when they accept a terms of service agreement.
But tech companies don't make that easy. They draft pages of complex, incomprehensible legal jargon to discourage users from learning about collection practices. TOS Chat is a response to those barriers. It connects GPT to an external vector database to let users "chat" with company documents.
TOS Chat Versus ChatGPT
TOS Chat runs on the same language model as ChatGPT (GPT 4) but it has some added functionality that make it much better suited for handling legal documents.
Sources
ChatGPT doesn't provide sources for its answers. It also rarely admits to not knowing the answer to a question. The only way to be sure ChatGPT is not hallucinating in its answer is by reading the terms of service, which nobody wants to do. On the other hand, by storing legal documents in a vector database, TOS Chat can provide the exact quote it used to contextualize its answer.
Current information
The second downside of using ChatGPT for documents is that companies like to change their agreements. Since ChatGPT has knowledge cutoffs and doesn't operate on the most up to date data, it won't have access to the changes. However, since TOS Chat simply uses PDFs for information, it can always have the most up to date data on a company's collection practices.
How does TOS Chat work?
Let's take a closer look at the architecture of the TOS Chat system.
PDF Ingestion
Since GPT only accepts text as an input, I need to break the PDF of a document into its text content. I'll also need to break the text content up into chunks because GPT has a limit on the amount of tokens it can handle. A 'token' is a part of a word, like a syllable, and both the user's question and the AI's answer need to fit within the token limit. This token limit is way too low to think about pasting the entire document into the query, so only chunks that are relevant to the user's question should be added as context.
Text Splitting and Parsing
PDFs can be difficult to work with because they often contain elements like headers, footers, images, and tables which make parsing the text more challenging.
To resolve this, we first convert the PDF document into plain text so it looks similar to a markdown file. Then, we break the text into smaller units, a method called "chunking". In our case, we need to create chunks that are small enough to fit within the token limit of the GPT-4 model, but also large enough to contain meaningful information.
I chose to chunk the text every 800 characters, but that number is somewhat arbitrary. As long as you’re getting at least a couple sentences in each chunk, it’ll be okay.
Creating LangChain Documents
The next step is to convert these chunks of text into LangChain "documents". LangChain is a framework that makes interacting with LLM (Large Language Model) APIs easier. A LangChain “document” is a format for storing chunked text.
The chunked text is stored along with metadata that helps trace it back to its origin in the parent document.
Uploading Text Chunks to Pinecone
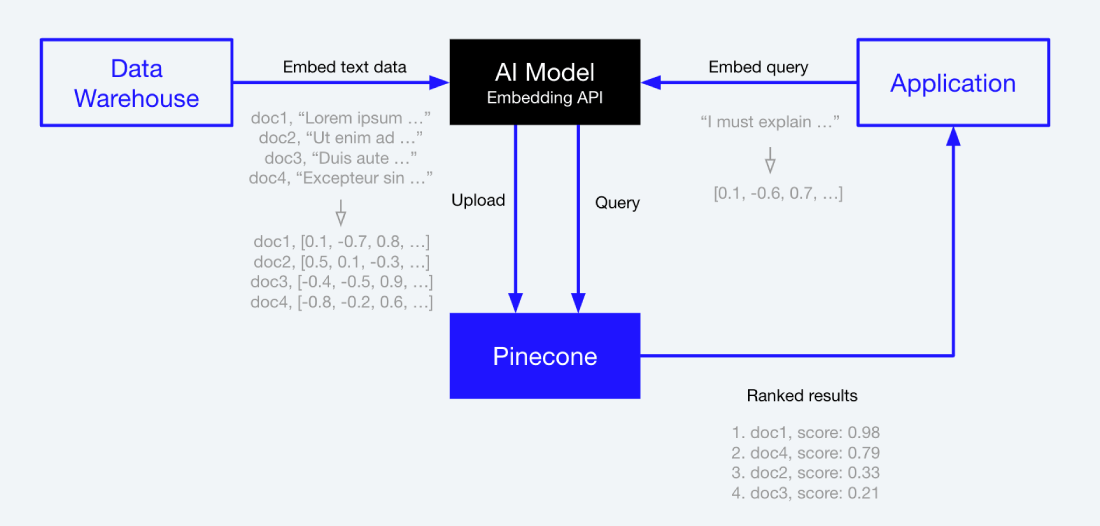
Before the text chunks are uploaded to the database, they need to be converted to vectors.
I do this with OpenAI’s text-embedding-ada-002 model, which generates an embedding for each text chunk.
Embeddings are 1536 dimension vectors that try to extract the “meaning” of the provided text.
Every embedding has 1536 dimensions, regardless of the length of the source text.
Our new embeddings are then uploaded to Pinecone (a cloud vector store).
Pinecone is searched by comparing a query vector to the stored vectors using cosine similarity (or other norms). This is better than a traditional database because it will find chunks that are related in meaning to the user's question instead of in format.
Each embedding is stored in Pinecone under a namespace corresponding to its parent PDF document. This architecture isolates searches to specific documents, making the system highly efficient and scalable.

Now, when a user asks a question about a specific TOS document, we can search the corresponding namespace in Pinecone for the most relevant LangChain documents, send these documents to GPT-4, and get an accurate, sourced answer in return.
Flycatcher - Waitlist Builder
Build your custom branded waitlist, collect insights about your subscribers, and send email campaign...

Object Recognition in Autonomous Rover
Adding a human detection system to a food delivery robot that serves boarding students on campus who...
Playlist Assist - Spotify Auto-DJ
Spotify companion app that creates beat-matched transitions within your Spotify playlist. Remotely ...
All Posts